
They are the people who made artificial intelligence what it is. They built the datasets, designed the architecture, and trained the systems that now write our emails, generate our code, and pass the bar exam. And increasingly, quietly, they are all working on the same problem—a problem that implies today’s most powerful AI, for all its staggering capability, is still missing something fundamental. World models, the industry now agrees, represent the next decisive leap in artificial intelligence (Goldman Sachs Global Institute, 2026). But even as the race accelerates, a critical omission remains: these models are being trained almost exclusively on physics and pixels, not on human decision data.
The missing half of the equation
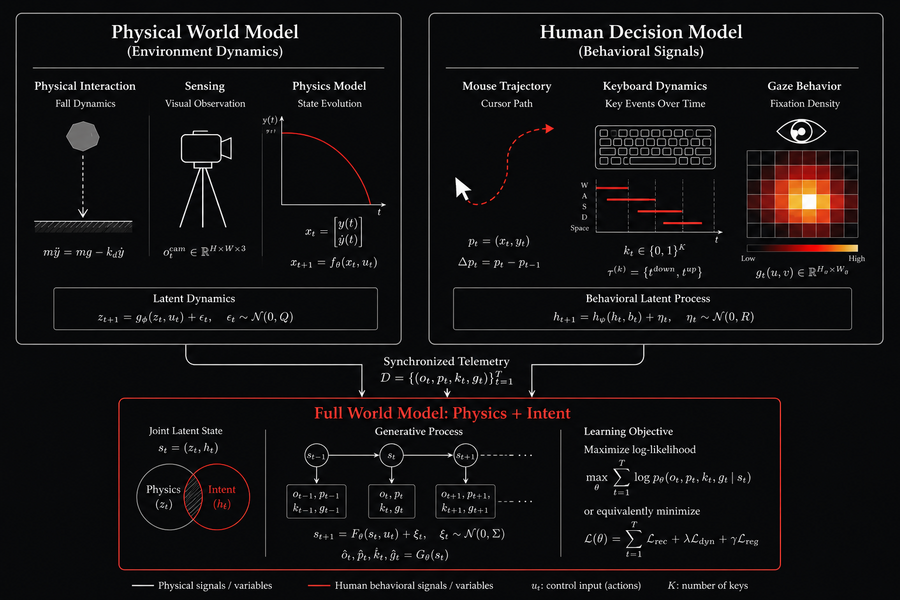
World models are exactly what they sound like: internal representations that allow an AI to simulate future outcomes, test hypotheses, and plan strategically (Hackernoon, 2025). As a Goldman Sachs report put it, today’s LLMs “lack the internal sense of the world those patterns describe” — they “understand how our world works based on the data and text to which they have been exposed,” but they “do not possess first-principles understanding of physics, motion, light, action/reaction, or other fundamental properties of our universe” (Lee & Keyserling, 2026). A world model fixes that. It gives AI a causal understanding of reality — a way to reason about what will happen next, not just what word comes next (Capgemini, 2026).
But there is a subtle but devastating oversight in almost every world model being built today. The vast majority focus exclusively on physical telemetry — camera paths, object positions, physics metadata. They learn how a rock falls, how light reflects, how a car accelerates. What they do not learn is why a human would choose to move left instead of right, or how hesitation looks in a mouse trajectory, or what a flick of the eyes reveals about intent before an action is taken.
The two frontiers: physical vs. social world models
The same Goldman Sachs report draws a critical distinction. Physical world models teach AI the governing logic of the material world: gravity, friction, thermodynamics, fluid dynamics. Virtual (or social) world models pursue a parallel ambition in human systems — digital environments populated by AI agents with goals, memories, and incentives, each designed to approximate a real‑world behavioral profile (Goldman Sachs, 2026). The physical side is already well‑funded and heavily researched. The social side — the side that requires understanding human decision‑making, not just human motion — remains largely untouched.
Yet understanding human behavior is arguably more important for the kinds of AI applications that will define the next decade: autonomous systems that must collaborate with people, agents that negotiate in markets, assistants that anticipate user needs. A world model that cannot predict why a human hesitates before clicking “buy” is a world model that cannot truly understand e‑commerce. A world model that cannot distinguish between a confident keystroke and a nervous one is a world model that cannot build trust.
The data wall and the way through
The broader AI industry is hitting a hard limit. Public web data — the fuel for the last five years of progress — is nearly exhausted. According to internal estimates, less than 5% of remaining web‑scale content meets the quality and licensing standards suitable for frontier training (SignalFire, 2025). Synthetic data has reached its own limits, with models increasingly overfitting on their own outputs. The next breakthrough, industry leaders now agree, will not come from scale but from specificity: expert‑driven, domain‑specific data that captures judgment, reasoning, and decision‑making (SignalFire, 2025).
For world models, this means the frontier is shifting from “how much physics data can we scrape or simulate?” to “how can we capture the human telemetry that turns raw physics into intentional action?” The companies and research labs that recognise this first will build the AI systems that actually work in the world (Fortune, 2026).
What human decision data actually looks like
The term “human decision data” sounds abstract. In practice, it is concrete, measurable, and already validated in academic research. Three streams are particularly valuable:
- Mouse trajectories — velocity, curvature, micro‑adjustments, click timing. These reveal not just what the user selected, but how they arrived at that decision. A hesitant, winding path suggests uncertainty; a direct, ballistic flick signals expertise. Behavioral fingerprinting research has shown that machine‑generated mouse movements are trivially distinguishable from human ones, precisely because they lack this natural “slow‑acceleration, peak‑speed, deceleration” curve (BEACON dataset, 2026).
- Keystroke dynamics — inter‑key intervals, hold durations, typing rhythms. These expose cognitive load, fatigue, and emotional state. The same sequence of inputs typed at 50ms intervals versus 200ms intervals tells a radically different story about the user’s confidence and attention.
- Gaze tracking — fixations, saccades, scanpaths. Where the eyes look — and where they do not — reveals what information the human considered important. In the Atari‑HEAD dataset, researchers found that removing peripheral visual information from the training signal caused action‑prediction accuracy to drop by 35‑44%, while removing explicit gaze information caused only a 2‑3% drop — meaning human decision‑making depends far more on information outside the current focus of attention than on the focus itself (Krauss et al., 2026).
Microsoft’s WHAM: proof that human telemetry works
In 2025, Microsoft Research published the World and Human Action Model (WHAM) in Nature, demonstrating that a generative model trained on human gameplay data could predict both game visuals and controller actions with remarkable consistency and diversity (Kanervisto et al., 2025). WHAM was trained on one year’s worth of anonymised gameplay from 27,990 players of Ninja Theory’s Xbox game Bleeding Edge, capturing a wide range of behaviors and interactions (Microsoft WHAM model card). The model was able to generate consistent game sequences and showed evidence of capturing the 3D structure of the game environment, the effects of controller actions, and the temporal structure of the game (WHAM documentation).
WHAM is significant not because it is the first human‑action model — but because it proves that human decision data can be collected at scale, anonymised safely, and used to train generative models that behave like people. The same approach can be extended to mouse telemetry, keystroke dynamics, and gaze tracking — the very streams that Relemetry is designed to capture.
Why this matters for Relemetry
The AI industry is converging on a consensus: world models are the future, and the future requires data that does not yet exist at scale. Physical telemetry — engine data, camera paths, physics simulations — is already well‑served by companies like Origin Lab. But the other half of the equation — the human decision data that turns physics into intent — remains almost entirely untapped.
Relemetry is building the missing half. Our datasets combine high‑frame‑rate screen recordings, detailed keyboard telemetry, and precise mouse‑movement data — all synchronised, all anonymised, all collected with explicit player consent from games with permissive Terms of Service. We are not competing with Origin Lab; we are complementing them. A world model trained on engine telemetry alone knows how a rock falls but not why a player dodges. Together, they form the foundation of AI that can truly act in the world — with physics and purpose.
References
- Goldman Sachs Global Institute. (2026). “When AI learns how the world works.” George Lee & Dan Keyserling, authors.
- Capgemini. (2026). “World Models: the answer to reliable AI?” Jonathan Aston.
- SignalFire. (2025). “Why expert data is becoming the new fuel for AI models.”
- Fortune. (2026). “AI models are choking on junk data.”
- Krauss, H., et al. (2026). “Estimating Central, Peripheral, and Temporal Visual Contributions to Human Decision Making in Atari Games.” arXiv:2604.04439.
- Kanervisto, A., Bignell, D., et al. (2025). “World and Human Action Models towards gameplay ideation.” Nature, 638(8051), 656–663.
- Microsoft Research. (2025). “WHAM model card.” Hugging Face / Nature.
- Bougie, N., et al. (2026). “AlignUSER: Human-Aligned LLM Agents via World Models for Recommender System Evaluation.” arXiv:2601.00930.
- Singh, I., et al. (2026). “BEACON: A Multimodal Dataset for Learning Behavioral Fingerprints from Gameplay Data.” arXiv:2605.10867.
- DreamDojo. (2026). “Scaling Robot World Models with 44,000+ Hours of Egocentric Human Video.”