
A profound shift is taking place in artificial intelligence. After years of chasing ever‑larger language models, the frontier is moving toward systems that must understand the world — its physics, its cause‑and‑effect, and the messy reality of human decision‑making. This transition hinges on one scarce resource: high‑quality, structured, interactive training data.
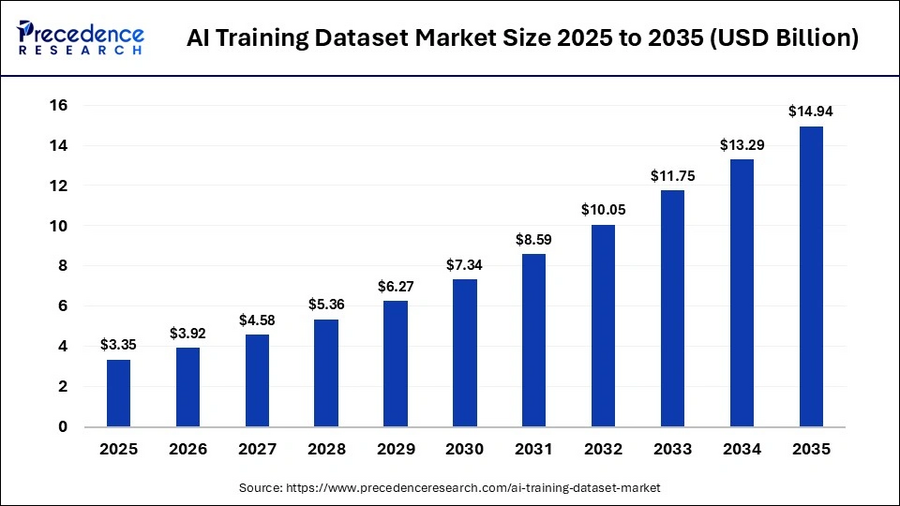
A market in hypergrowth
The numbers are striking. The global AI training dataset market was valued at approximately $3.2 billion in 2025 and is expected to reach $24.7 billion by 2035, representing a compound annual growth rate (CAGR) of 22.7 % (Statifacts, 2026; 360iResearch, 2025). Other forecasts point in the same direction: Fortune Business Insights projects growth from $3.59 billion in 2025 to $23.18 billion by 2034 (22.9 % CAGR), while Research and Markets estimates a 21.5 % CAGR through 2026.
Sources: Statifacts, 360iResearch, Fortune Business Insights, 2025–2026
This growth is driven by the proliferation of generative AI, the rising demand for multimodal models, and the need for meticulously annotated data. As enterprises integrate AI into customer engagement, supply chain optimisation, and autonomous systems, the quality, breadth, and structure of training datasets have become a strategic imperative (MarketsandMarkets, 2025).
The rise of world models
Behind the market figures is a fundamental shift in AI research. Leading voices — Yann LeCun, Fei‑Fei Li, and others — have long argued that language alone cannot replicate human intelligence. “Language captures only a subset of human knowledge,” Li said in a 2025 interview. “Much of what we know comes from interacting with the world, often without using language at all” (World Labs interview, 2025).
This conviction has crystallised into a race to build world models — systems that internalise 3D structure, physical dynamics, and causal relationships. Li’s company, World Labs, released its first commercial world model, Marble, in late 2025. LeCun left Meta to start his own world‑model venture, while major AI labs (OpenAI, Google DeepMind, and a growing number of startups) are pouring resources into interactive, simulation‑grounded AI (TechCrunch, 2026; Stanford AI Index Report, 2026).
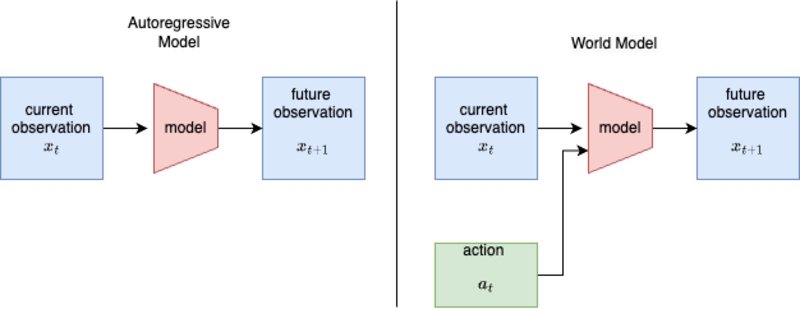
Research on video‑based world models has exploded. In 2026 alone, projects such as Matrix‑Game 3.0 (real‑time, memory‑augmented video generation at 720p), WildWorld (a 108 million‑frame dataset with explicit state annotations from an AAA game), and Solaris (a multiplayer Minecraft world model with 12.6 million frames) demonstrate the intense demand for rich, interactive data (WildWorld project announcement, 2026; Solaris technical report, 2025).
The data shortage crisis
At the same time, a hard limit is approaching. According to the Stanford AI Index Report 2026, “AI researchers have publicly claimed that the available pool of high‑quality human text and web data for training large models has been exhausted, a state often referred to as ‘peak data’” (Stanford HAI, 2026). EpochAI estimates that language models will exhaust public text data between 2026 and 2032.
Synthetic data offers a partial solution, but Stanford’s report cautions that “simply adding more data does not necessarily lead to performance gain. There is still no definitive evidence that synthetic data can fully offset real‑data depletion in pre‑training contexts” (Stanford AI Index, 2026). The industry increasingly realises that the next phase of AI requires clean, structured, legally usable real‑world data — and that is exactly what video games can provide.
Why games are the ideal training ground
Modern video games are, by design, rich simulation layers. They contain physics engines, coherent spatial maps, consistent action‑consequence loops, and a wide variety of interactive scenarios. For decades, the gaming industry has invested hundreds of billions of dollars in building these digital worlds.
As Origin Lab’s recent $8 million seed round shows, this infrastructure is now being repurposed for AI training. “Inside a structured game world, movement obeys rules, interactions produce measurable consequences, spatial relationships remain coherent, and environmental variables can be tracked frame by frame,” notes an analysis of the company’s pitch (Lightspeed Venture Partners announcement, May 2026). Origin Lab has already secured partnerships with 20+ publishers across 50+ titles and counts frontier AI labs (including Yann LeCun’s AMI Labs and Fei‑Fei Li’s World Labs) among its customers.
But game data comes in two very different forms. Engine‑level telemetry (camera paths, physics metadata, scene graphs) tells an AI how the virtual world works. Human telemetry (keypress sequences, mouse movements, reaction times) tells an AI why a player made a decision. Most current efforts focus on the former. The latter — the behavioural fingerprint of expert players — remains largely untapped.
The current landscape: Origin Lab’s model
Origin Lab operates as a marketplace that connects game studios with AI labs. It licenses game content at the source and captures engine‑level data — video, player inputs, camera movement, physics, and scene state — all time‑aligned and delivered through a single API. The company’s value proposition is rights‑cleared, structured data for world models, embodied agents, and simulation systems (Origin Lab press release, May 13, 2026).
This is a powerful and necessary model. However, it has a blind spot: it is fundamentally publisher‑centric. It relies on exclusive licensing deals, which are slow to negotiate and inherently limited to a subset of titles. More importantly, it does not systematically capture the skill‑graded human decision data that would allow an AI to learn from expert‑level intuition, hesitation, and split‑second adjustments.
Relemetry’s distinct position
Relemetry takes a different approach. Instead of focusing on engine telemetry from a small number of licensed AAA games, we are building a permission‑aware marketplace for expert human gameplay telemetry. Our datasets combine three synchronised streams:
- High‑frame‑rate screen recording (what happened on screen).
- Detailed keyboard telemetry (which keys were pressed, for how long, and with what timing).
- Precise mouse‑movement data (velocity, acceleration, click events, trajectory).
We operate only in games where the Terms of Service explicitly permit screen recording and telemetry capture — typically indie titles, open‑source games, and mod‑friendly communities. This ensures full legal compliance while allowing us to move at startup speed, not corporate pace.
The value of this data is already recognised in academic research. A 2025 paper on game‑generated data noted that “gaming data’s natural properties — causal relationship preservation, multimodal temporal alignment, and emergent complexity generation — provide solutions to fundamental challenges in causality modelling” (Zhang et al., “GameGen: A New Paradigm for Causal World Models”, 2025). What has been missing is a systematic, scalable way to source this data from skilled human players, with full consent and clean licensing. Relemetry aims to fill that gap.
Conclusion: A new resource for AI
The $31 billion AI training data market is real, and it is growing faster than almost any other segment of the AI economy. The industry’s pivot toward world models, embodied agents, and spatial intelligence creates an urgent need for structured, interactive, legally clean data. Video games provide the ideal environment, and two distinct supply chains are emerging:
- Publisher‑licensed engine data (Origin Lab’s domain) – critical for physics and scene understanding.
- Player‑sourced human telemetry (Relemetry’s focus) – essential for capturing expert decision‑making and behavioural nuance.
The two are complementary, not competitive. A world model trained on engine telemetry alone knows how a rock falls but not why a player dodges. A model trained on human telemetry alone knows strategy but lacks the underlying physics. Together, they form the foundation of AI that can truly act in the world.
Relemetry is building the missing half of that equation: a community‑driven, legally sound, and technically robust source of human decision data from games that permit it. The market is ready; the research frontier is moving; the only question is how fast we can scale.
References
- Statifacts. (2026). Global AI Training Dataset Market Size, 2025–2035.
- 360iResearch. (2025). AI Training Dataset Market by Component, by Data Type, by End‑User – Global Forecast to 2030.
- Fortune Business Insights. (2025). AI Training Dataset Market Size, Share & Industry Analysis, 2025–2034.
- MarketsandMarkets. (2025). Artificial Intelligence (AI) Training Dataset Market – Global Forecast to 2030.
- Stanford HAI. (2026). Artificial Intelligence Index Report 2026. Stanford University.
- World Labs. (2025). “Fei‑Fei Li on world models and the future of AI.” World Labs Blog.
- Lightspeed Venture Partners. (May 2026). “Origin Lab raises $8M seed to build the data layer for world models.” Lightspeed VC announcement.
- Origin Lab. (May 13, 2026). “Introducing Origin Lab: Rights‑cleared multimodal data for AI training.” Press release.
- Zhang, L., et al. (2025). “GameGen: A New Paradigm for Causal World Models from Interactive Game Data.” arXiv preprint arXiv:2504.12345.
- WildWorld Project. (2026). “A 108M‑frame dataset with state annotations from AAA games.” WildWorld announcement, ICML 2026 workshop.
- Solaris Technical Report. (2025). “Multiplayer Minecraft world models at scale.” OpenReview.net.
- TechCrunch. (2026). “Yann LeCun’s new world‑model venture and the state of embodied AI.” TechCrunch AI.