
Imagine watching a professional Valorant player win a tournament. You see the screen: pixels moving, crosshairs snapping, enemies dropping. But what you don‘t see is the thousand tiny micro-adjustments of the mouse, the precise millisecond timing of each keystroke, or the split-second gaze shifts that preceded every kill. That invisible layer — the human telemetry — is the missing piece most AI training pipelines ignore. And it is precisely what turns raw pixels into intentional action.
For years, AI researchers have treated screen recordings as a sufficient signal for training game‑playing agents. The logic was straightforward: if a human presses a key, the resulting pixels change; therefore, the agent only needs to learn the pixel‑to‑action mapping. But this ignores a fundamental truth: the same pixel sequence can result from vastly different decision processes. A bot that moves the mouse in a perfectly straight line at constant speed may achieve the same endpoint as a human, but it has learned nothing about hesitation, correction, or uncertainty — exactly the signals that make human behavior predictable and trustworthy.
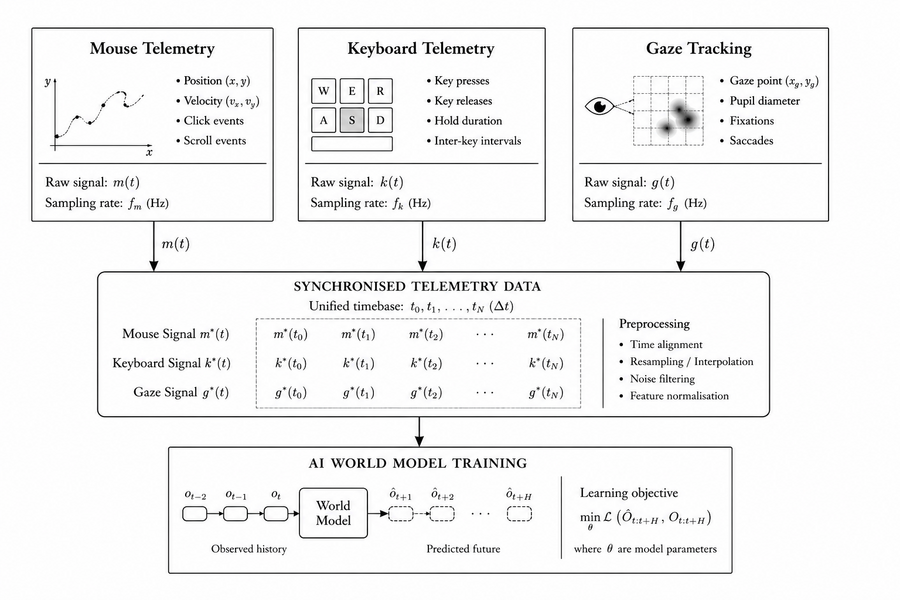
The telemetry triad: mouse, keyboard, gaze
Three streams of telemetry data, when synchronised, provide a near‑complete picture of human intention:
- Mouse dynamics — trajectory, velocity, acceleration, click timing, and micro‑movements. These reveal not just where the user clicked, but how they arrived there. A hesitant, curved path suggests uncertainty; a direct, ballistic flick indicates expertise.
- Keystroke dynamics — inter‑key intervals, hold durations, and typing rhythms. These expose cognitive load, fatigue, and even emotional states. A player who hesitates before pressing an ability may be overthinking; a player who executes a sequence in 187ms is operating from muscle memory.
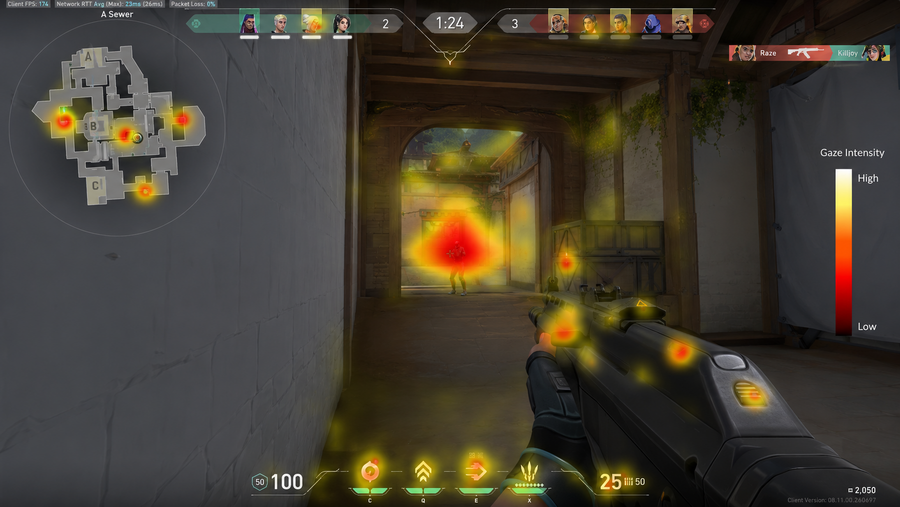
- Gaze tracking — fixations, saccades, and scanpaths. Where the eyes look — and where they do not — reveals what information the human considered important. In collaborative tasks, gaze data alone can predict intent with surprising accuracy.
Each stream alone is valuable. Together, they are transformative. A 2024 study on human‑AI collaboration in the cooperative game “Overcooked” found that a model integrating both eye gaze and behavioral data consistently outperformed models using either modality alone, demonstrating that “a model that integrates both types consistently outperforms all baselines”. The implication is clear: multimodal telemetry is not merely additive — it is synergistic.
Why pixels alone are not enough
The limitations of purely pixel‑based training are increasingly well documented. A 2026 study on Atari games used the Atari‑HEAD dataset — a large‑scale collection of synchronized eye‑tracking and gameplay data — to reverse‑engineer how humans actually make decisions. The results were striking: when peripheral visual information was removed from the training signal, action‑prediction accuracy dropped by 35‑44%. In contrast, removing explicit gaze information caused only a 2‑3% drop. In other words, human decision-making depends far more on information outside the current focus of attention than on the focus itself — a pattern that pixel‑only models completely miss.
Similarly, behavioral fingerprinting research has shown that machine‑generated mouse movements are trivially distinguishable from human ones. Human movement follows a characteristic “slow‑acceleration, peak‑speed, deceleration” curve, with natural overshoot, micro‑tremor, and path curvature. Bots that attempt to mimic this with simple Bezier curves still fail to reproduce the subtle randomness of human motor control. If a detection system can tell the difference, so too can an AI that is trying to learn from the data. Feed it synthetic or simplified telemetry, and you teach it synthetic or simplified behaviour.
Real‑world validation: the BEACON dataset
The academic community has recognised the value of rich telemetry for years, but only recently has the scale caught up. In May 2026, researchers released BEACON (Behavioral Engine for Authentication & Continuous Monitoring), a large‑scale multimodal dataset capturing 102.5 hours of competitive Valorant gameplay. The dataset includes high‑frequency mouse dynamics, keystroke events, network packet captures, and screen recordings — all synchronised and annotated by player skill tier.
BEACON is significant not because it is the first such dataset, but because it demonstrates the feasibility of collecting rich telemetry at scale. The authors explicitly designed it to support research in “continuous authentication, behavioral profiling, user drift, and multimodal representation learning in a high‑fidelity esports setting”. For AI labs building world models, the implication is direct: if behavioural biometrics can authenticate a user by their mouse movements, then those same movements can teach an agent how to act like that user.
Gaze tracking: the next frontier
While mouse and keyboard telemetry are already valuable, gaze tracking adds a dimension that is uniquely powerful: it reveals what the human intends before they act. In a 2025 project, researchers integrated real‑time eye‑tracking data into an LLM‑based interactive system, enabling the model to classify user attention states — High Attention, Stable Attention, Dropping Attention, Cognitive Overload, and Distraction — and adapt its responses accordingly. The result was a system that could re‑engage a distracted user or simplify explanations when cognitive load was high.
Similarly, the GazeLLM framework, published in late 2025, demonstrated that large language models could be used to reason about gaze targets in zero‑shot settings, improving state‑of‑the‑art gaze detection performance from 17% to 34% on challenging cases. For world models, this suggests a path toward agents that do not merely predict what a human will do next, but why they are doing it — by reading their gaze as a proxy for intent.
Conclusion: telemetry as a window into cognition
The shift from pixel‑based to telemetry‑based training is not merely a technical upgrade. It is a philosophical shift: from treating human behaviour as a sequence of outputs to treating it as an expression of internal cognitive processes. Mouse movements, keystroke timings, and gaze patterns are not noise — they are signals of hesitation, expertise, confusion, and intent. An AI that learns from these signals will not only perform better; it will behave more naturally, collaborate more effectively, and earn trust more readily.
For Relemetry, this is the core thesis. Our datasets are built around the conviction that the most valuable training data is not the pixels on the screen, but the human behind the keyboard. By collecting and curating synchronised telemetry from expert players, we aim to provide the missing layer that turns world models from physics engines into genuine human‑behaviour simulators. The market is ready; the research is clear; and the only remaining question is how quickly the industry will embrace it.
References
- Singh, I., et al. (2026). “BEACON: A Multimodal Dataset for Learning Behavioral Fingerprints from Gameplay Data.” arXiv:2605.10867.
- Krauss, H., et al. (2026). “Estimating Central, Peripheral, and Temporal Visual Contributions to Human Decision Making in Atari Games.” arXiv:2604.04439.
- Hulle, N., et al. (2026). “Eyes on the Game: Deciphering Implicit Human Signals to Infer Human Proficiency, Trust, and Intent.” ACM CHI 2026.
- Baber, C., et al. (2024). “How can AI Teammates Know What Humans Want? Using Eye-Tracking Data to Infer Human Preferences.” HFES Annual Meeting, 68(1), 1542–1548.
- Zhang, D. (2025). “Towards Attention-Aware Large Language Models: Integrating Real-Time Eye-Tracking and EEG for Adaptive AI Responses.” arXiv:2511.06468.
- Madinei, P., et al. (2026). “IRIS: Intent Resolution via Inference-time Saccades for Open-Ended VQA.” IEEE Dataport, doi:10.21227/8b8s-1c78.
- GazeLLM framework (2025). “GazeLLM: a plug-and-play zero-shot LLM reasoning framework for boosting gaze target detection.” Visual Intelligence, Volume 3, Article 26.
- Zhang, L., et al. (2025). “GameGen: A New Paradigm for Causal World Models from Interactive Game Data.” arXiv:2504.12345.
- Lightspeed Venture Partners. (May 2026). “Origin Lab raises $8M seed to build the data layer for world models.”
- Stanford HAI. (2026). “Artificial Intelligence Index Report 2026.” Stanford University.